English to Katakana with Sequence to Sequence in TensorFlow
This is a reposted of my Medium article (to try Bloggie platform).
All data and code are available on Github.
If you are a non-specialist deep-learning enthusiasm like me, you probably feel it's difficult applying deep NLP techniques, e.g. Sequence-To-Sequence, into real-world problems. I’ve found most datasets or corpuses aside from class tutorials, e.g. chat dialogs, are often very big (e.g. WMT’15 in Tensorflow’s Neural Machine Translation tutorial is 20GB) and sometime difficult to access (e.g. Annotated English Gigaword). The training time on those large dataset also takes several hours to several days.
As it happens, I’ve found writing Japanese Katakana a perfect practice problem for machine learning. It could be viewed as a smaller version of machine translation. As you will see, with just around 4MB of training data and a few hours of training on a non-GPU machine, we can build a reasonably good model to translate English words to Katakana characters.
At the end of this tutorial, you will be able to build a machine learning model to write your name in Japanese.
Basic Katakana
(Feel free to skip this part if you know some Japanese)
Katakana is a subset of Japanese characters. Each Katakana character represents a single Japanese syllable and has a specific pronouncing sound. To write a word in Katakana is to combine the syllable of each character.
Here is one simple example,
- カ pronounces “ka”
- ナ pronounces “na”
- タ pronounces “ta”. Its variance, ダ, pronounces “da”
Putting those together, you can write カナダ (Ka-na-da) = Canada.
This Japanese writing system is used for writing words borrowing from other languages.
- バナナ (ba-na-na) : Banana
- バーベキュー(baa-be-ki-yuu) : Barbecue
- グーグル マップ (guu-gu-ru map-pu) : Google Maps
It’s also used for writing non-Japanese names:
- ジョン・ドウ (ji-yo-n do-u): John Doe
- ドナルド・ダック(do-na-ru-do da-k-ku): Donald Duck
- ドナルド・トランプ (do-na-ru-do to-ra-n-pu): Donald Trump
You can look up the character-to-English-syllable from this website.
Or start learning Japanese today 😃
Dataset
Our training data is English/Japanese pairs of Wikipedia titles, which usually are names of persons, places, or companies. We use only the articles that Japanese title consists of only Katakana characters.
The raw data can be download from dbpedia website. The website provide Labels datasets that each line contains the resource ID and the title in local language.
<http://wikidata.dbpedia.org/resource/Q1000013> <http://www.w3.org/2000/01/rdf-schema#label> "ジャガー・XK140"@ja .
<http://wikidata.dbpedia.org/resource/Q1000032> <http://www.w3.org/2000/01/rdf-schema#label> "アンスクーリング"@ja .
...
<http://wikidata.dbpedia.org/resource/Q1000000> <http://www.w3.org/2000/01/rdf-schema#label> "Water crisis in Iran"@en .
<http://wikidata.dbpedia.org/resource/Q1000001> <http://www.w3.org/2000/01/rdf-schema#label> "Gold Cobra"@en .
...We can parse Japanese and English title out, join them by the resource ID, and filter only the articles with Japanese title in all Katakana. By following this instruction, I created ~100k joined title pairs.
The built dataset can be downloaded directly here.
Sequence-to-Sequence in Keras
Sequence-to-Sequnce (aka. Seq2Seq) is a technique to train a model that predict output sequnce from input sequence. There are a lot of documents and tutorials that explain the model in details:
- Tensorflow’s Sequence-to-Sequnce tutorial. link
- The Sequence-to-Sequnce paper. link
- A lecture by Quoc Le, the paper’s author. link
- CS20si Lecture 13. link
In this tutorial, I assume you have some knowledge about Recurrent Neural Network (RNN and LSTM) and Sequence-to-Sequence model. I also assume that you has some experience with Keras.
We will build a simple Sequence-to-Sequence model (without attention) as shown in the diagram in Keras.
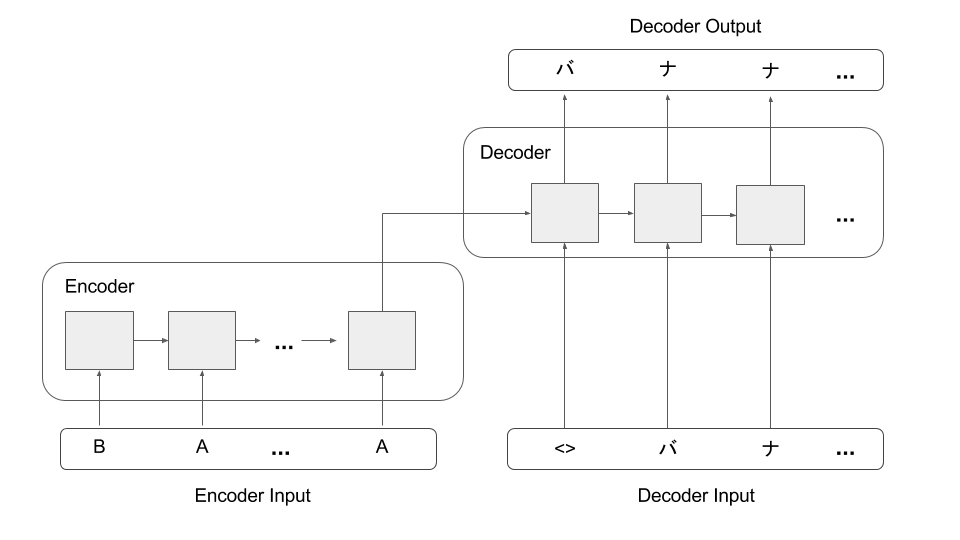
- The model have two part, Encoder and Decoder.
- The encoder read a sequence of English characters and produce an output vector
- The decoder read the encoder output and a sequence of (shifted) Katakana characters, then predict the next Katana characters in the sequence.
- The model have two inputs for encoder and decoder, and one output from the decoder.
Data Transformation
As show in the diagram, our model’s input is a sequence of characters. But, Keras doesn’t actually take characters as input. We need to transform English and Katakana characters into IDs.
To do that, we also need to build encoding dictionary and its reverse use for decoding the results later.
# Lets training input/output is a list of English/Katakana titles
training_input = [‘Gail Hopkins', ...]
training_output = [u'ゲイル・ホプキンス', ...]
PADDING_CHAR_CODE=0
START_CHAR_CODE=1
# Building character encoding dictionary
def encode_characters(titles):
count = 2
encoding = {}
decoding = {1: 'START'}
for c in set([c for title in titles for c in title]):
encoding[c] = count
decoding[count] = c
count += 1
return encoding, decoding, count
# With encoding dictionary, transform the data into an matrix
def transform(encoding, data, vector_size):
transformed_data = np.zeros(shape=(len(data), vector_size))
for i in range(len(data)):
for j in range(min(len(data[i]), vector_size)):
transformed_data[i][j] = encoding[data[i][j]]
return transformed_data
# Build encoding dictionary
english_encoding, english_decoding, english_dict_size = encode_characters(training_input)
japanese_encoding, japanese_decoding, japanese_dict_size = encode_characters(training_output)
# Transform the data
encoded_training_input = transform(english_encoding, training_input, vector_size=20)
encoded_training_output = transform(japanese_encoding, training_output, vector_size=20)We also need to:
- Pad the Decoder Input with “START” character (as shown in the diagram)
- Transform Decoder Output into One-hot encoded form
# Encoder Input
training_encoder_input = encoded_training_input
# Decoder Input (need padding by START_CHAR_CODE)
training_decoder_input = np.zeros_like(encoded_training_output)
training_decoder_input[:, 1:] = encoded_training_output[:,:-1]
training_decoder_input[:, 0] = START_CHAR_CODE
# Decoder Output (one-hot encoded)
training_decoder_output = np.eye(japanese_dict_size)[encoded_training_output]The Encoder

Our input is a sequence of character. The first step in transform each input character into a dense vector by Embedding layer.
We use a Recurrent layer (LSTM) to encoder the input vectors. The output of this encoding step with be the output LSTM at the final time step. This can be done in Keras by setting return_sequences=False.
encoder = Embedding(english_dict_size, 64, input_length=INPUT_LENGTH, mask_zero=True)(encoder_input)
encoder = LSTM(64, return_sequences=False)(encoder)The more powerful encoder can be build by stacking multiple layers of LSTM (with return_sequences=True), but this will make the model take significant longer time to train.
encoder = Embedding(input_dict_size, 64, input_length=INPUT_LENGTH, mask_zero=True)(encoder_input)
encoder = LSTM(64, return_sequences=True)(encoder)
…
encoder = LSTM(64, return_sequences=True)(encoder)
encoder = LSTM(64, return_sequences=False)(encoder)The Decoder

Decoder is more complicate, but not by much.
Similar to the encoding step, decoder input is a sequence of character. We also pass the decoder input into an Embedding layer to transform each character into a vector.
We, again, pass the embedded input into an LSTM. However, this time, we want the LSTM to produce an output sequence (return_sequnece=True). We also use the output from encoder as the initial_state for the LSTM.
Finally, we use (TimeDistributed) Dense Layer with softmax activation to transform each LSTM’s output to the final output.
decoder = Embedding(japanese_dict_size, 64, input_length=OUTPUT_LENGTH, mask_zero=True)(decoder_input)
decoder = LSTM(64, return_sequences=True)(decoder, initial_state=[encoder, encoder])
decoder = TimeDistributed(Dense(japanese_dict_size, activation="softmax"))(decoder)Building and Training the Model
model = Model(inputs=[encoder_input, decoder_input], outputs=[decoder])
model.compile(optimizer='adam', loss='categorical_crossentropy')
model.fit(x=[training_encoder_input, training_decoder_input],
y=[training_decoder_output],
verbose=2,
batch_size=64,
epochs=20)The final step is to create a Keras’s Model object. Our model has two inputs (from the encoder and decoder) and one output (from the decoder).
We compile the model with Adam optimizer and Categorical Cross-Entropy loss function, then fit the model with the transformed data.
The training usually takes around an hour (on CPU).
Write Katakana from English words
We can apply the trained model to write Katakana for any given English input. In this article, we will use a greedy decoding technique (there is more accurate beam search technique) as following:
- Create
encoder_inputfrom the English input. - Create
decoder_inputas an empty sequence with only START character. - Use the model to predict
decoder_outputfromencoder_inputanddecoder_input.

- Take the most-likely first character of the
decoder_outputsequence as the first Katakana output. Copy the output character to the next character indecoder_input.
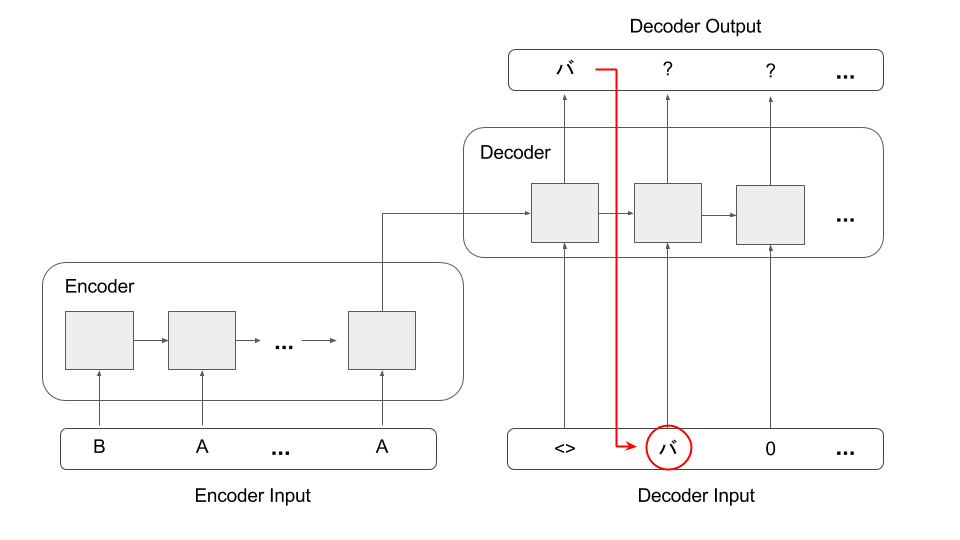
- Keep repeating step 3–4. Every time, we generate one Katakana output and assign the character as the next decoder_input character.

def generate_katakana_sequence(english_text):
encoder_input = transform(input_encoding, [text.lower()], INPUT_LENGTH)
decoder_input = np.zeros(shape=(len(encoder_input), OUTPUT_LENGTH), dtype='int')
decoder_input[:,0] = START_CHAR_CODE
for i in range(1, OUTPUT_LENGTH):
output = model.predict([encoder_input, decoder_input]).argmax(axis=2)
decoder_input[:,i] = output[:,i]
return decoder_input[0, 1:]We also need character decoding and some wrapper functions.
def decode_sequence(decoding, sequence):
text = ''
for i in sequence:
if i == 0:
break
text += output_decoding[i]
return text
def to_katakana(text):
output_sequence = generate_katakana_sequence(text)
return decode_sequence(japanese_decoding, output_sequence)The Results
If you have common Western-style names, the model should be able to write your name correctly.
- James ジェームズ
- John ジョン
- Robert ロベルト
- Mary マリー
- Patricia パトリシア
- Linda リンダ
Of course, our simple model is not perfect. Because we train the model with mostly place and people names, some English words may not be written correctly (but almost).
- Computer コンプーター (correctly, コンピューター)
- Taxi タクシ (correctly, タクシー).
Also, our simple model don’t have the attention mechanism. It has to encode, compress and remember the whole input sequence in a single vector (there is only one line connection between encoder and decoder).
So, writing Katakana for a long English words can be challenging. My name, for example, "Wanasit Tanakitrungruang" is written as “ワナシート・タナキトリングラウン” (correctly ワナシット・タナキットルンアン).
The model actually doesn’t do all that bad, because most Japanese I know can't write my name correctly either 😃. However, making the model that write long Thai names in Katakana correctly would be an interesting next step.
Wanasit T
Clap to support the author, help others find it, and make your opinion count.